Vertalingen: "English" |
Gebruik Swagger Json voor Github Copilot
updated on 2025-04-25
Hé allemaal! Ik heb een productiviteitshack om te delen die me enorm veel tijd bespaart met het werken met API's. Laat me je zien hoe je Swagger JSON-documentatie kunt gebruiken met VS Code Copilot om API-integratiecode te schrijven in minuten in plaats van uren. Wanneer je gaat werken met Large Language Models (LLM's) is precisie alles - hoe specifieker en gedetailleerder je input, hoe beter en nauwkeuriger je resultaten zullen zijn.
In deze korte notes maken we gebruik van de gestructureerde data die Swagger ons biedt en gebruiken we deze informatie in VS code zodat copilot functies kan genereren op basis van deze data:
1. Verkrijg Je Swagger JSON
Wat is swagger?
Swagger laat je API een universele taal spreken die machines kunnen begrijpen, en dat is behoorlijk gaaf! Wanneer je API zijn structuur deelt via een YAML- of JSON-bestand en volgens de OpenAPI-specificatie, kunnen we automatisch mooie API-documentatie maken, codebibliotheken genereren en zelfs tests opzetten.
Download json
Je kunt de content van jouw API-specificatie direct downloaden of kopiëren via een directe link of ga naar https://{fqdn}/swagger en klik op de downloadlink.

Swagger download link locatie
Afhankelijk van je configuratie, sla je het json-bestand op of maak je het aan in je project.
2. Laad het in VS Code
Laad (externe) content
Laad met #fetch
Het is nu mogelijk om het swagger.json-bestand rechtstreeks in je project te laden met behulp van de #fetch-opdracht. Dit bespaart je de moeite van het handmatig downloaden en opslaan van het bestand. Gebruik gewoon de opdracht #fetch gevolgd door de URL van je Swagger JSON-bestand.
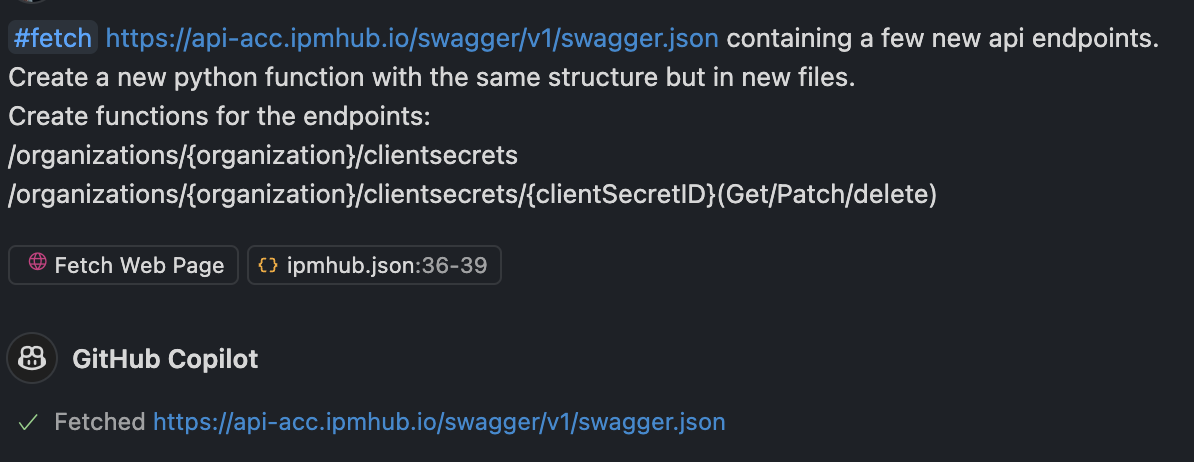
Swagger download link locatie
Nu we de specificaties van onze API klaar hebben binnen ons project kunnen we dit gaan gebruiken.
In dit voorbeeld heb ik al een Pyhon class die de logging, authenticatie, de CRUD-acties en de afhandeling van de asynchrone/synchrone requests in Python regelt. We hoeven alleen nog maar extra endpoints toe te voegen.
Laad data in Github Copilot
Om ervoor te zorgen dat GitHub Copilot alle informatie over de API heeft, moeten we het bestand in de huidige chat als context laden.
Gebruik hiervoor de #file variabele om het swagger.json bestand te laden.
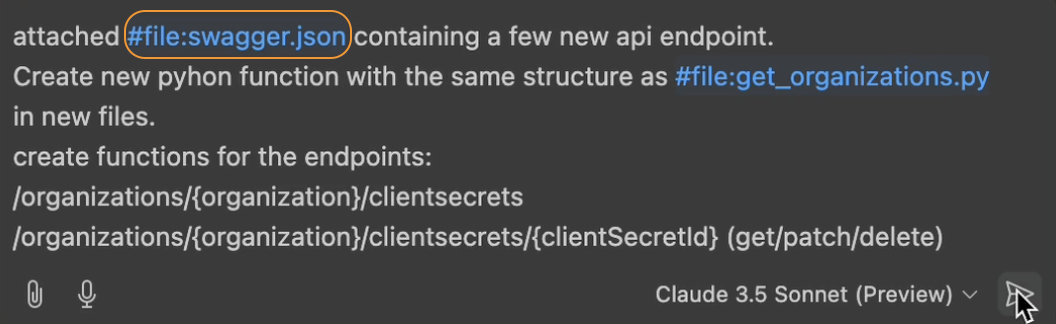
Gebruik de #file variabele om het swagger bestand te laden.
Laad extra context van je applicatie
Het laden van de Swagger JSON is maar de helft van het verhaal - je moet Copilot ook laten zien hoe je wilt dat je code gestructureerd wordt. In mijn geval had ik al bestaande API-functies die mijn gewenste codestyle en patronen volgden.
Om Copilot dit patroon te laten begrijpen, laadde ik een voorbeeldbestand (get_organizations.py) dat functies bevatte geschreven in mijn gewenste stijl. Net als bij het Swagger-bestand gebruik je de #file variabele om dit aan Copilot's context toe te voegen:
#file:get_organizations.py
Deze stap is cruciaal omdat het Copilot helpt bij:
- Het matchen van je bestaande codestijl
- Het gebruiken van dezelfde foutafhandelingspatronen
- Het volgen van je project's functienaamconventies
- Het behouden van consistentie in je codebase
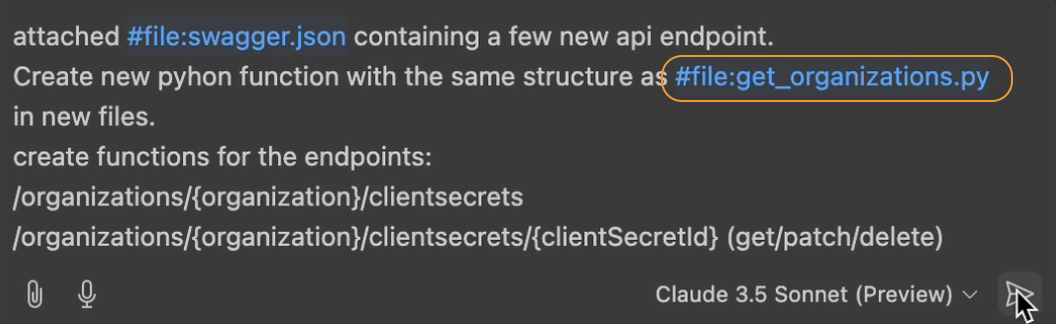
Gebruik de #file variabele om een voorbeeldbestand te laden.
De Prompt
Nu de prompt, nou dit is eigenlijk niet zo spannend, ik vraag CoPilot gewoon wat ik wil zien, maar het is belangrijk om zo exact mogelijk te zijn.
1Attached `#file:swagger.json` containing a few new api endpoints.
2Create a new Python function with the same structure as `#file:get_organizations.py` in new files.
3Create function for the endpoints:
4/organizations/{organizations}/clientsecrets
5/organizations/{organizations}/clientsecrets/{clientSecretId} (get/patch/delete)
Laten we de prompt ontleden:
Attached #file:swagger.json containing a few new api endpoints.
Rechttoe rechtaan, wijs Copilot de juiste richting.Create a new Python function with the same structure as #file:get_organizations.py in new files.
Ook vrij rechttoe rechtaan, maar hier vertel ik CoPilot hoe het eindresultaat eruit moet zien, en dat ik het in nieuwe bestanden wil hebben.
Wanneer je de "new file" niet vermeldt, zal het waarschijnlijk de nieuwe functies toevoegen aanget_organization.pyCreate function for the endpoints: {endpoint name}
Omdat deswagger.jsonveel meer endpoints heeft die ik al in mijn project heb opgenomen, is dit waar ik de prompt afbaken.(get/patch/delete)
Hier zorg ik ervoor dat Copilot begrijpt (voor de zekerheid) dat hij functies moet maken voor alle CRUD-operaties.
Wees zo precies mogelijk
Ik moet eerlijk zijn, in de Conclusie hieronder vertel ik je dat het me maar twee minuten kostte. Dat was simpelweg niet waar, het waren er drie. Waarom? Ik was vergeten Copilot te vertellen dat hij ook asynchrone functies moest maken, waardoor ik alleen synchrone functies kreeg. Dit is waarom je zo precies mogelijk moet zijn en altijd de resultaten moet controleren, want de bron (get_organization.py) bevat zowel asynchrone als synchrone functies.
Uitvoering
Het laatste wat je moet doen voordat je achterover kunt leunen is de uitvoering. In dit scenario heb je twee verschillende benaderingen.
Copilot chat
Dit genereert de functie in het chatvenster, en dan moet je de code nog aan je project toevoegen.Edit with Copilot
Dit maakt de wijzigingen direct voor je in je project, in dit geval het maken van een nieuw bestand
Als laatste optie kun je het model instellen dat je wilt gebruiken, ik gebruik zelf het meest Claude 3.5 Sonnent, en schakel alleen over als het te traag wordt.
In de screencast video hieronder zie je dat ik Edit with Copilot gebruik in combinatie met Claude 3.5 Sonnent.
Blog gaat verder onder de video
3. Conclusie en TLDR
Dit is waarom ik dit zo gaaf vind: Wat me vroeger ongeveer 30 minuten kostte aan documentatie lezen, boilerplate code schrijven (oké, kopiëren/plakken (en kleine foutjes maken)), en testen, kost nu minder dan 2 minuten.
Waarom werkt dit zo goed?
De sleutel hier is dat Swagger JSON een complete, gestructureerde beschrijving van je API geeft die Copilot perfect kan begrijpen. Het is alsof je Copilot een gedetailleerde kaart van je API geeft - geen giswerk meer over endpoints, parameters of responseformaten. Hoewel Swagger veel afhandelt, moeten de API-ontwikkelaars hun deel doen in het maken van goede documentatie, maar eerlijk gezegd is dit ook iets waar Copilot je bij kan helpen. Onthoud, hoe beter gedocumenteerd je Swagger-bestand is, hoe betere resultaten je zult krijgen. Het is de moeite waard om wat extra tijd te besteden aan het zorgen dat je API-documentatie top is - het zal zich dubbel en dwars terugbetalen tijdens het ontwikkelen!
TLDR
Stap 1: Verkrijg Je Swagger JSON
- Ga naar je API's Swagger UI (
/swagger) - Download of kopieer de JSON-specificatie
- Sla het op in je projectmap
- Ga naar je API's Swagger UI (
Stap 2: Zet VS Code op
- Open je project in VS Code
- Laad het swagger.json bestand
- Voeg voorbeeldbestanden toe voor context
Stap 3: Gebruik Github Copilot
- Gebruik
#filevariabele om swagger.json als context te laden - Laad voorbeeldbestanden om gewenste codestructuur te tonen
- Schrijf een precieze prompt die beschrijft wat je nodig hebt
- Kies tussen Copilot chat of Edit with Copilot
- Selecteer je voorkeursmodel (bijv. Claude 3.5 Sonnet)
- Gebruik
Pro Tip: Wees zo specifiek mogelijk in je prompts - vermeld of je async functies, nieuwe bestanden of specifieke CRUD-operaties wilt. Hoe preciezer je bent, hoe beter de resultaten!
Dat is het! Je hebt zojuist een taak van 30 minuten veranderd in een klus van 2 minuten. Happy coding! 🚀